 This article is the 6th in a series on about my adventures developing a web application with HTML5, Play Scala, CoffeeScript and Jade. Previous articles can be found at:
This article is the 6th in a series on about my adventures developing a web application with HTML5, Play Scala, CoffeeScript and Jade. Previous articles can be found at:
- Integrating Scalate and Jade with Play 1.2.3
- Trying to make CoffeeScript work with Scalate and Play
- Integrating HTML5 Boilerplate with Scalate and Play
- Developing with HTML5, CoffeeScript and Twitter's Bootstrap
- Play Scala's Anorm, Heroku and PostgreSQL Issues
Last week, I wrote about my adventures with Anorm and mentioned I'd made some improvements to Scalate Play interoperability. First of all, I've been using a Scalate trait and ScalateTemplate class to render Jade templates in my application. I described this setup in my first article on Scalate and Play.
Adding SiteMesh Features and Default Variables
When I started making my app look good with CSS, I started longing for a feature I've used in SiteMesh. That is, to have a body id or class that can identify the page and allow per-page CSS rules. To do this with SiteMesh, you'd have something like the following in your page:
<body id="signup"/>
And then read it in your decorator:
<body<decorator:getProperty property="body.class" writeEntireProperty="true"/>>
As I started looking into how to do this, I came across Play Scala's ScalaController and how it was populating Play's default variables (request, response, flash, params, etc.). Based on this newfound knowledge, I added a populateRenderArgs() method to set all the default variables and my desired bodyClass variable.
def populateRenderArgs(args: (Symbol, Any)*): Map[String, Any] = {
val renderArgs = Scope.RenderArgs.current();
args.foreach {
o =>
renderArgs.put(o._1.name, o._2)
}
renderArgs.put("session", Scope.Session.current())
renderArgs.put("request", Http.Request.current())
renderArgs.put("flash", Scope.Flash.current())
renderArgs.put("params", Scope.Params.current())
renderArgs.put("errors", validationErrors)
renderArgs.put("config", Play.configuration)
// CSS class to add to body
renderArgs.put("bodyClass", Http.Request.current().action.replace(".", " ").toLowerCase)
renderArgs.data.toMap
}
implicit def validationErrors:Map[String,play.data.validation.Error] = {
import scala.collection.JavaConverters._
Map.empty[String,play.data.validation.Error] ++
Validation.errors.asScala.map( e => (e.getKey, e) )
}
After adding this method, I was able to access these values in my templates by defining them at the top:
-@ val bodyClass: String
-@ val params: play.mvc.Scope.Params
-@ val flash: play.mvc.Scope.Flash
And then reading their values in my template:
body(class=bodyClass)
...
- if (flash.get("success") != null) {
div(class="alert-message success" data-alert="alert")
a(class="close" href="#") &×
| #{flash.get("success")}
- }
...
fieldset
legend Leave a comment →
div.clearfix
label(for="author") Your name:
input(type="text" name="author" class="xlarge" value={params.get("author")})
div.clearfix
label(for="content") Your message:
textarea(name="content" class="xlarge") #{params.get("content")}
div.actions
button(type="submit" class="btn primary") Submit your comment
button(type="reset" class="btn") Cancel
For a request like Home/index, the body tag is now rendered as:
<body class="home index">
This allows you to group CSS styles by Controller names as well as by method names.
Next, I started developing forms and validation logic. I quickly discovered I needed an action() method like the one defined in ScalaTemplate's TemplateMagic class.
def action(action: => Any) = {
new play.mvc.results.ScalaAction(action).actionDefinition.url
}
Since TemplateMagic is an inner class, I determined that copying the method into my ScalateTemplate class was the easiest workaround. After doing this, I was able to import the method and use it in my templates.
-import controllers.ScalateTemplate._
...
form(method="post" class="form-stacked" id="commentForm"
action={action(controllers.Profile.postComment(workout._1.id()))})
After getting the proper URL written into my form's action attribute, I encountered a new problem. The Play Scala Tutorial explains validation flow as follows:
if (Validation.hasErrors) {
show(postId)
} else {
Comment.create(Comment(postId, author, content))
Action(show(postId))
}
However, when I had validation errors, I end up with the following error:
Could not load resource: [Timeline/postComment.jade]
To fix this, I added logic to my Scalate trait that looks for a "template" variable before using Http.Request.current().action.replace(".", "/") for the name. After making this change, I was able to use the following code to display validation errors.
if (Validation.hasErrors) {
renderArgs.put("template", "Timeline/show")
show(postId)
} else {
Comment.create(Comment(postId, author, content))
Action(show(postId))
}
Next, I wanted to give child pages the ability to set content in parent pages. With SiteMesh, I could use the <content> tag as follows:
<content tag="underground">
HTML goes here
</content>
This HTML could then be retrieved in the decorator using the <decorator:getProperty> tag:
<decorator:getProperty property="page.underground"/>
With Scalate, I found it equally easy using the captureAttribute() method. For example, here's how I captured a list of an athlete's workouts for display in a sidebar.
- captureAttribute("sidebar")
- Option(older).filterNot(_.isEmpty).map { workouts =>
.older-workouts
h3
| Older workouts
span.from from this app
- workouts.map { workout =>
- render("workout.jade", Map('workout -> workout, 'mode -> "teaser"))
- }
- }
- }
Then in my layout, I was able to retrieve this and display it. Below is a snippet from the layout I'm using (copied from Twitter's Bootstrap example). You can see how the sidebar is included in the .span4 at the end.
-@ val sidebar: String = ""
...
.container
.content
.page-header
h1
= pageHeader
small
= pageTagline
.row
.span10
!~~ body
.span4
= unescape(sidebar)
footer
View vs. Render in Scalate
In the sidebar code above, you might notice the render() call. This is the Scalate version of server-side includes. It works well, but there's also a view() shortcut you can use if you want to have templates for rendering your model objects. I quickly discovered it might be difficult to use this feature in my app because my object was Option[(models.Workout, models.Athlete, Seq[models.Comment])] instead of a simple object. You can read the view vs. render thread on the Scalate Google Group if you're interested in learning more.
Scalate as a Module
The last enhancement I attempted to make was to put Scalate support into a Play module. At first, I tried overriding Play's Template class but ran into compilation issues. Then Guillaume Bort (Play's lead developer) recommended I stick with the trait approach and I was able to get everything working. I looked at the outdated play-scalate module to figure out how to add Scala support to build.xml and copied its 500.scaml page for error reporting.
In order to get line-precise error reporting working, I had to wrap a try/catch around calling Scalate's TemplateEngine.layout() method. Again, most of this code was copied from the outdated play-scalate module.
case class Template(name: String) {
def render(args: (Symbol, Any)*) = {
val argsMap = populateRenderArgs(args: _*)
val buffer = new StringWriter()
var context = new DefaultRenderContext(name, scalateEngine, new PrintWriter(buffer))
try {
val templatePath = new File(Play.applicationPath+"/app/views","/"+name).toString
.replace(new File(Play.applicationPath+"/app/views").toString,"")
scalateEngine.layout(templatePath + scalateType, argsMap)
} catch {
case ex:TemplateNotFoundException => {
if(ex.isSourceAvailable) {
throw ex
}
val element = PlayException.getInterestingStrackTraceElement(ex)
if (element != null) {
throw new TemplateNotFoundException(name,
Play.classes.getApplicationClass(element.getClassName()), element.getLineNumber());
} else {
throw ex
}
}
case ex:InvalidSyntaxException => handleSpecialError(context,ex)
case ex:CompilerException => handleSpecialError(context,ex)
case ex:Exception => handleSpecialError(context,ex)
} finally {
if (buffer.toString.length > 0)
throw new ScalateResult(buffer.toString,name)
}
}
}
...
private def handleSpecialError(context:DefaultRenderContext,ex:Exception) {
context.attributes("javax.servlet.error.exception") = ex
context.attributes("javax.servlet.error.message") = ex.getMessage
try {
scalateEngine.layout(scalateEngine.load(errorTemplate), context)
} catch {
case ex:Exception =>
// TODO use logging API from Play here...
println("Caught: " + ex)
ex.printStackTrace
}
}
private def errorTemplate:String = {
val fullPath = new File(Play.applicationPath,"/app/views/errors/500.scaml").toString
fullPath.replace(new File(Play.applicationPath+"/app/views").toString,"")
}
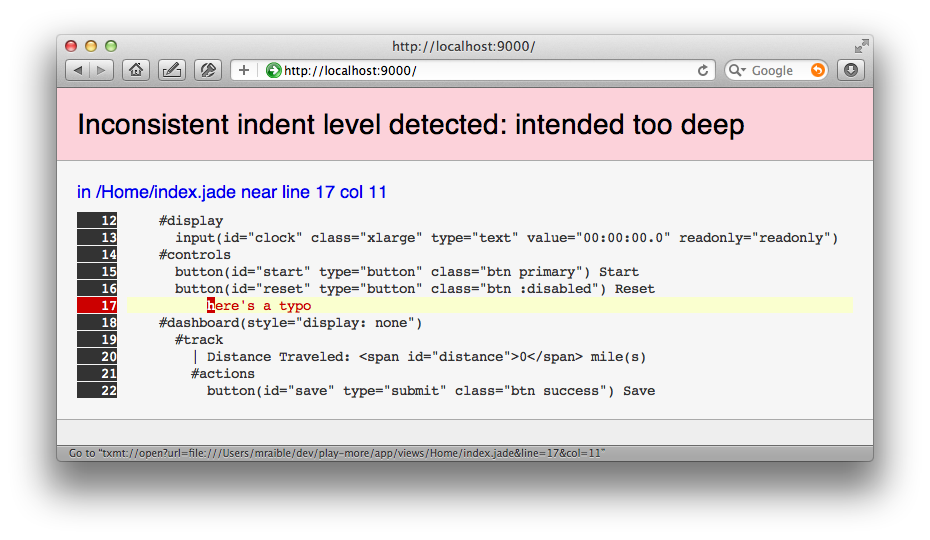
Once I had this in place, error messages from Scalate are much better. Not only do I see the error in my browser, but I can click on the offending line to open it directly in TextMate.
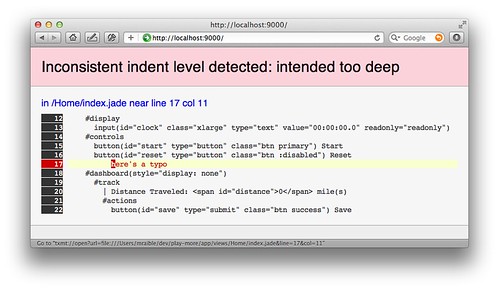
I've published my play-scalate module on GitHub so others can try it out. To give it a whirl, add the following to your dependencies.yml:
- upgrades -> play-scalate 0.1
repositories:
- upgrades:
type: http
artifact: "http://static.raibledesigns.com/[module]-[revision].zip"
contains:
- upgrades -> *
Then add with play.modules.scalate.Scalate to your controllers and call the render() method.
Summary
After using Scalate and Play for almost 3 months, I'm really enjoying the combination. When I first integrated Scalate with a simple trait, the error messages were always in the console. Now that I've borrowed some smarts from Play's ScalaController and play-scalate's error reporting, I feel like it's practically a built-in solution. I was easily able to integrate my desired SiteMesh features and it even allows reusable template blocks. In the end, it's just Scala and Scalate does a good job of allowing you to leverage that.
Other thoughts:
- If you're writing a lot of Jade and familiar with HTML, Don Park's html2jade is a great tool that comes with Scalate support.
- I'm really enjoying writing CSS with LESS, particularly the ability to nest rules and have programming features. The only issue I've seen is IntelliJ's LESS plugin only does code-completion for variables rather than CSS values.
- The Play Framework Cookbook is a great reference for learning how to write modules. Not only does it explain how to create modules, it has some great real-world examples for doing bytecode enhancement, implementing message queues, using Solr and how to do production monitoring.
If this series of articles has intrigued you and you'll be at Devoxx next week, you should stop by my talk on Thursday afternoon. In addition, there's several other Play talks at Devoxx and a possible meetup on Wednesday. Check out the Devoxx, anyone? thread for more information.
Update: There's one thing I forgot to mention about the Play Scalate Module. When I had Scalate integrated in my app with a trait, I only included the scalate-core and scalate-util JARs in dependencies.yml:
- org.fusesource.scalate -> scalate-core 1.5.2-scala_2.8.1:
transitive: false
- org.fusesource.scalate -> scalate-util 1.5.2-scala_2.8.1:
transitive: false
However, when I created the play-scalate module, I allowed more dependencies.
- org.fusesource.scalate -> scalate-core 1.5.2-scala_2.8.1:
exclude:
- javax.servlet -> *
- com.sun.jersey -> *
- org.osgi -> *
- org.fusesource.scalate -> scalate-util 1.5.2-scala_2.8.1
Because Scalate depends on
Logback, debug messages started showing up in my console. To fix this, I created
conf/logback.xml in my project and filled it with the following XML.
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
</configuration>
This reduces the logging and allows me to increase Scalate's logging if I ever have the need.



")

")