RE: Moving from Spring to Java EE 6: The Age of Frameworks is Over
Last Tuesday, Cameron McKenzie wrote an interesting article on TheServerSide titled Moving from Spring to Java EE 6: The Age of Frameworks is Over. In this article, Cameron says the following:
J2EE represents the past, and Java EE 6 represents the future. Java EE 6 promises us the ability to go beyond frameworks. Frameworks like Spring are really just a bridge between the mistakes of the J2EE past and the success of the Java EE 6 future. Frameworks are out, and extensions to the Java EE 6 platform are in. Now is the time to start looking past Spring, and looking forward to Seam and Weld and CDI technologies.
He then links to an article titled Spring to Java EE - A Migration Experience, an article written by JBoss's Lincoln Baxter. In this article, Lincoln talks about many of the technologies in Java EE 6, namely JPA, EJB, JSF, CDI and JAX-RS. He highlights all the various XML files you'll need to know about and the wide variety of Java EE 6 application servers: JBoss AS 6 and GlassFish v3.
I don't have a problem with Lincoln's article, in fact I think it's very informative and some of the best documentation I've seen for Java EE 6.
I do have some issues with Cameron's statements that frameworks are mistakes of the J2EE past and that Java EE 6 represents the future. Open source frameworks made J2EE successful. Struts and Hibernate came out in the early days of J2EE and still exist today. Spring came out shortly after and has turned into the do-everything J2EE implementation it was trying to fix. Java EE 6 might be a better foundation to build upon, but it's certainly not going to replace frameworks.
To prove my point, let's start by looking at the persistence layer. We used to have Hibernate based on JDBC, now we have JPA implementations built on top of the JPA API. Is JPA a replacement for all persistence frameworks? I've worked with it and think it's a good API, but the 2.0 version isn't available in a Maven repo and Alfresco recently moved away from Hibernate (which == JPA IMO) to iBATIS for greater data access layer control and scalability. Looks like the age of frameworks isn't over for persistence frameworks.
The other areas that Java EE 6 covers that I believe frameworks will continue to excel in: EJB, CDI, JSF and JAX-RS. Personally, I don't have a problem with EJB 3 and think it's a vast improvement on EJB 2.x. I don't have an issue with CDI either, and as long as it resembles Guice for dependency injection, it works for me. However, when you get into the space I've been living in for the last couple years (high-traffic public internet sites), EJB and things like the "conversation-scope" feature of CDI don't buy you much. The way to make web application scale is to eliminate state and cache as much as possible, both of which Java EE doesn't provide much help for. In fact, to disable sessions in a servlet-container, you have to write a Filter like the following:
public class DisabledSessionFilter extends OncePerRequestFilter {
/**
* Filters requests to disable URL-based session identifiers.
*/
@Override
protected void doFilterInternal(final HttpServletRequest request,
final HttpServletResponse response,
final FilterChain chain)
throws IOException, ServletException {
HttpServletRequestWrapper wrappedRequest = new HttpServletRequestWrapper(request) {
@Override
public HttpSession getSession(final boolean create) {
if (create) {
throw new UnsupportedOperationException("Session support disabled");
}
return null;
}
@Override
public HttpSession getSession() {
throw new UnsupportedOperationException("Session support disabled");
}
};
// process next request in chain
chain.doFilter(wrappedRequest, response);
}
}
What about JAX-RS? Does it replace the need for frameworks? I like the idea of having a REST API in Java. However, its reference implementation is Jersey, which seems more like a framework than just Java EE. If you choose to use JAX-RS in your application, you still have to choose between CXF, Jersey, RESTEasy and Restlet. I compared these frameworks last year and found the Java EE implementation lacking in the features I needed.
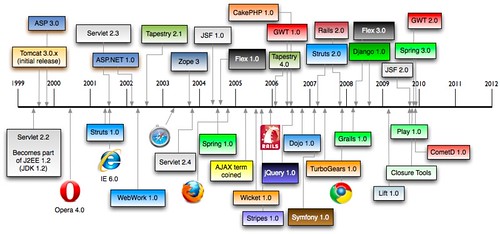
Finally, let's talk about my-least-framework-web-framework: JSF. The main reason I don't like JSF is because of its 1.x version. JSF 1.0 was released a year before the Ajax term was coined (see timeline below). Not only did it take forever to develop as a spec, but it tried to be a client-component framework that was very stateful by default.

Now that JSF 2.0 is out, it has Ajax integrated and allows you to use GET instead of POST-for-everything. However, the only people that like Ajax integrated into their web frameworks are programmers scared of JavaScript (who probably shouldn't be developing your UI). Also, the best component development platform for the web is JavaScript. I recommend using an Ajax framework for your components if you really want a rich UI.
Sure you can use the likes of Tapestry and Wicket if you like POJO-based web development, but if you're looking to develop a webapp that's easy to maintain and understand, chances are that you'll do much better with traditional MVC frameworks like Spring MVC and Struts 2. The simplicity and popularity of Rails and Grails further emphasize that developers prefer these types of web frameworks.
Another reason I don't like JSF: there's very few developers in the wild happy with it. The major promoters of JSF are book authors, trainers, Java EE Vendors and MyFaces developers. Whenever I speak at conferences, I ask folks to raise their hands for the various web frameworks they're using. I always ask the JSF users to keep their hands up if they like it. Rarely do they stay up.
So it looks like we still need web frameworks.
Eberhard Wolff has an interesting post where he defends Spring and talks about the productivity comparisons between Spring and Java EE. He recommends using Grails or Spring Roo if you want the level of productivity that Ruby on Rails provides. That's a valid recommendation if you're building CRUD-based webapps, but I haven't developed those in quite some time. Nowadays, the apps I develop are true SOFEA apps, where the backend serves up XML or JSON and the frontend client is HTML/JavaScript/CSS, Android, iPad or Sony Blu-Ray players. On my current project, our services don't even talk to a database, they talk to a CMS via RESTful APIs. We use Spring's RestTemplate for this and HttpClient when it doesn't have the features we need. Not much in Java EE 6 for this type of communication. Sure, Jersey has a client, but it's certainly not part of the Java EE spec.
As far as getting Ruby on Rails' zero-turnaround productivity, I don't need Grails or Spring Roo, I simply use IDEA and JRebel.
Conclusion
I don't see how new features in Java EE 6 can mean the age of frameworks is over. Java SE and J2EE have always been foundations for frameworks. The Java EE 6 features are often frameworks in themselves that can be used outside of a Java EE container. Furthermore, Java EE 6 doesn't provide all the features you need to build a high-scale web app today. There's no caching, no stateless web framework that can serve up JSON and HTML and no hot-reload productivity enhancements like JRebel. Furthermore, there's real excitement in Javaland for languages like Scala, Groovy and JRuby. All of these languages have web frameworks that've made many developers happy.
Here's to the Age of Frameworks - may it live as long as the JVM!
P.S. If you'd like to hear me talk about web frameworks on the JVM, I'll be speaking at The Colorado Springs Open Source Meetup and Devoxx 2010 in the near future.
")